Мы
привыкли, что для любого статистического показателя вычисляется p – вероятность ошибки. Данный показатель с точки
зрения эксперимента отражает вероятность принять нуль-гипотезу, т.е. гипотезу о
незначимости показателя. К примеру, для коэффициента корреляции p=0,5 свидетельствует о том, что вероятность принять
полученный коэффициент за незначимый равна 50%, а значение p=0,05 предполагает 5% вероятности принять
нуль-гипотезу. Соответственно, чем меньше p, тем лучше. Остаётся главный вопрос – откуда берется численное выражение
вероятности ошибки и почему иногда пишут, что за допустимое значение p берется p<=0,05 или p<=0,01 ?
Здесь мы не будем
обсуждать, как конкретно вычисляется p, так как, любая программа для статистических расчетов позволяет
автоматически вычислить вероятность ошибки. Здесь мы рассмотрим общий принцип
вычисления, рассмотрим сущность вероятности ошибки.
Для примера,
будем использовать коэффициент корреляции Пирсона и проведём небольшой эксперимент.
Для начала нам
понадобится две переменных. Не будем брать реальные данные и сгенерируем эти
переменные как случайные. Причем случайные числа будут браться из
привычного нормального распределения.
Количество случаев (условно, количество человек) будет равным 100.
После генерации
двух переменных посчитаем коэффициент корреляции между ними.
А теперь самое
главное: проделаем эти операции (генерирование и расчет коэффициента) 10000 раз. Много? Вручную это быстро не
посчитаешь, однако это позволяет сделать язык для статистического
программирования R.
В результате, мы
получаем 10 тыс. коэффициентов корреляции. Очевидно, что среди этого огромного
количества будут коэффициенты, которые встречаются очень часто и те, которые
можно встретить очень редко.
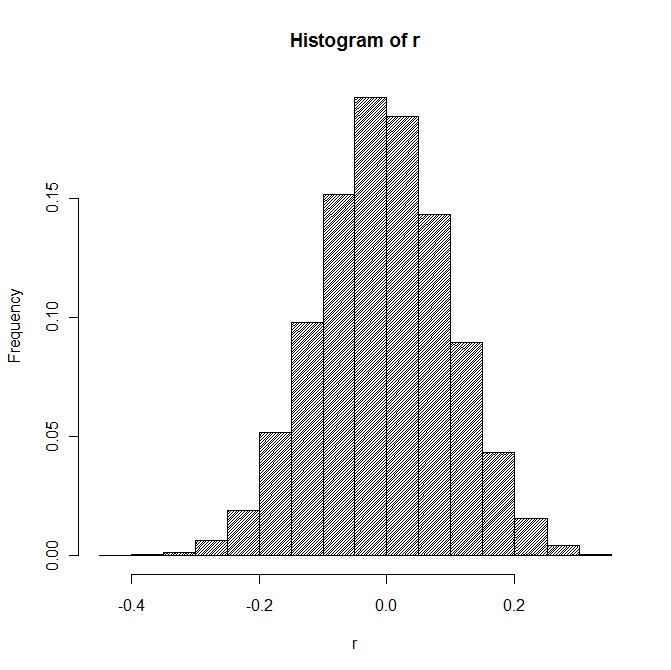
Построим
распределение этих коэффициентов.
Проанализируем
наш многотысячный массив коэффициентов: Среднее
арифметическое: -0.0001 Стандартное
отклонение: 0.10 Вероятность
встретить значения коэффициента от –0,1 до +0,1 равна 65%
Судя по всему,
значения близкие к 0 встречаются очень часто. А вот вероятность
коэффициента 0,35 равна 0,05% . Получается, что из 10 тыс. случаев только 5
сильно коррелируют. А теперь самое
главное.
Изначально мы
генерировали две случайные выборки по 100 случаев каждая. Как вы думаете, насколько
вероятно, что хотя бы 5% значений в этих двух рядах будут прямопропорционально
совпадать (конечно, совпадать не только
абсолютно, но и в некотором диапазоне)? Обращаясь к
природе коэффициента корреляции, мы можем сказать, что он как раз и отражает
то, насколько совпадают две величины, насколько они близки (прямо- или
обратнопропорционально). Конечно же,
случаи близости двух рядов очень редки, ведь ряды генерировались случайно,
поэтому будет редок и сильный коэффициент корреляции между ними. А значит, чем
менее вероятен коэффициент, тем он значимее, т.е. по сути – тем вероятнее он
соответствует тому самому редкому случаю совпадения. А теперь вернемся
к нашему сгенерированному распределению коэффициентов. И перерисуем его так,
чтобы вместо абсолютного количества было относительное. Относительное
количество – это вероятность выпадения значения, деленная на общее количество
значений (у нас всего 10 тыс.).
В статистике
вероятность обозначается p. Коэффициенты с маленькой вероятностью будут сообщать нам о редких
случаях. К примеру, вероятность достаточно сильного коэффициента r=0,35 равна 0,0005 , т.е. всего 0,05%. Для этого примера
будет справедливо записать, что вероятность совершить ошибку, сказав, что
коэффициент корреляции достоверен, равна 0,05%. Ведь этот коэффициент и
встречается ровно в 5 случаях из 10 тыс. случаев. Теперь вспомним
немного теории про гипотезы: Н0 – нулевая
гипотеза, предположение об отсутствии явления (в нашем случае - коэффициент
стремится к нулю). Н1 – гипотеза о
существовании явления (коэффициент стремится к единице). Основываясь на
этом, мы можем сказать, что вероятность отклонить Н1 равна 0,05%, а вероятность
принять ее равна 100-0,05 = 99,95%. До сих пор логика
вычисления p
была такова: высчитываем коэффициент, а затем находим его вероятность в
распределении. Однако, для нас, психологов и педагогов, намного привычнее
говорить о критическом значении какого-либо статистического показателя. Обычно
в скобках после показателя пишут, к примеру, р≤0,05. Рассуждая так, мы просто
идём в обратном порядке. Сначала заявляем вероятность, а затем находим значение
показателя при данной вероятности. В психологии принято заявлять вероятности
р≤0,1, р≤0,05, р≤0,01, р≤0,001. В точных науках берется гораздо меньшая
вероятность ошибки. Конечно, самим
считать вероятность слишком долго, проще это сделать в Excel или Calc
или в другой программе, поддерживающей статистические функции. А если под рукой
нет компьютера, но есть таблицы критических значений, то выяснить значимость
показателя также просто. В таблицах уже посчитаны значения показателя при
определенной его вероятности.
Описание тестов, их нормы, особенности применения, описание надежности и валидности. Идеи о том, как измерять психологические явления и создавать новые тесты.